
Over the past few months, AI chatbots like ChatGPT have captured the world's attention due to their ability to converse in a human-like way on just about any subject. But they come with a serious drawback: They can present convincing false information easily, making them unreliable sources of factual information and potential sources of defamation.
Why do AI chatbots make things up, and will we ever be able to fully trust their output? We asked several experts and dug into how these AI models work to find the answers.
“Hallucinations”—a loaded term in AI
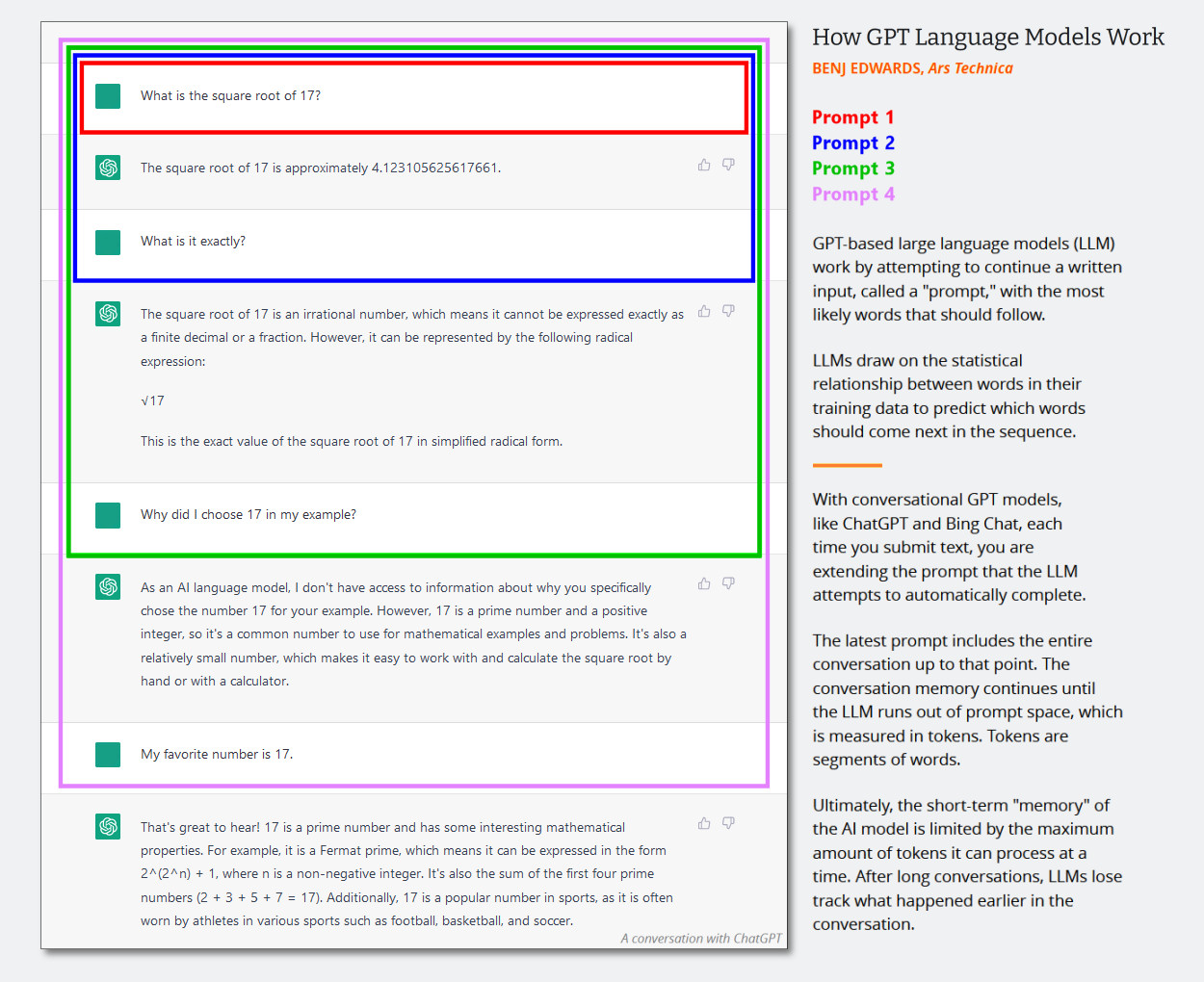
AI chatbots such as OpenAI's ChatGPT rely on a type of AI called a "large language model" (LLM) to generate their responses. An LLM is a computer program trained on millions of text sources that can read and generate "natural language" text—language as humans would naturally write or talk. Unfortunately, they can also make mistakes.
In academic literature, AI researchers often call these mistakes "hallucinations." But that label has grown controversial as the topic becomes mainstream because some people feel it anthropomorphizes AI models (suggesting they have human-like features) or gives them agency (suggesting they can make their own choices) in situations where that should not be implied. The creators of commercial LLMs may also use hallucinations as an excuse to blame the AI model for faulty outputs instead of taking responsibility for the outputs themselves.
Still, generative AI is so new that we need metaphors borrowed from existing ideas to explain these highly technical concepts to the broader public. In this vein, we feel the term "confabulation," although similarly imperfect, is a better metaphor than "hallucination." In human psychology, a "confabulation" occurs when someone's memory has a gap and the brain convincingly fills in the rest without intending to deceive others. ChatGPT does not work like the human brain, but the term "confabulation" arguably serves as a better metaphor because there's a creative gap-filling principle at work, as we'll explore below.







 Loading comments...
Loading comments...
